

结合索引设计、查询优化、硬件配置等多维度策略,并附具体示例:
一、索引优化(核心手段)
精准索引
为查询条件的字段创建单列或复合索引,尤其是高选择性字段(如主键、唯一键)。
-- 示例:为user_id字段创建索引 CREATE INDEX idx_user_id ON users(user_id);覆盖索引:若查询字段均包含在索引中,可避免回表操作。
-- 示例:索引覆盖查询 SELECT user_id, name FROM users WHERE user_id = 100; -- 假设索引为(user_id, name)复合索引顺序
遵循 最左前缀原则,将高频查询字段放在索引左侧。
-- 示例:复合索引优化 CREATE INDEX idx_status_created ON orders(status, created_at); -- 适合WHERE status=? ORDER BY created_at
二、查询语句优化
避免全表扫描
禁止使用
SELECT *,只查询必要字段。
-- 反例 SELECT * FROM users WHERE email = 'test@example.com'; -- 正例 SELECT id, name FROM users WHERE email = 'test@example.com';分页优化
避免大偏移量
LIMIT offset, size,改用 游标分页(基于 ID 或时间戳)。
-- 传统分页(低效) SELECT * FROM orders LIMIT 100000, 10; -- 游标分页(高效) SELECT * FROM orders WHERE id > 100000 ORDER BY id LIMIT 10;避免索引失效操作
禁止对索引列使用函数、计算或隐式类型转换。
-- 反例:索引失效 SELECT * FROM users WHERE DATE(created_at) = '2025-01-01'; -- 正例:利用索引 SELECT * FROM users WHERE created_at BETWEEN '2025-01-01 00:00:00' AND '2025-01-01 23:59:59';
三、表结构与存储优化
分区表
按时间或 ID 范围分区,减少单次查询扫描的数据量。
-- 示例:按年份分区 ALTER TABLE logs PARTITION BY RANGE (YEAR(created_at)) ( PARTITION p2023 VALUES LESS THAN (2024), PARTITION p2024 VALUES LESS THAN (2025), PARTITION pmax VALUES LESS THAN MAXVALUE );垂直拆分
将大字段(如 TEXT)或不常用字段拆分到副表,减少主表体积。
归档历史数据
将冷数据迁移到归档表,降低主表数据量。
四、数据库配置与硬件优化
调整缓冲池大小
增加
innodb_buffer_pool_size(建议为物理内存的 70%~80%)。
SET GLOBAL innodb_buffer_pool_size = 8G; -- 根据服务器内存调整使用 SSD 存储
SSD 的 I/O 性能远高于 HDD,尤其适合随机读写场景。
读写分离
主库处理写操作,从库处理读查询,分散负载。
五、高级技巧
延迟关联
先通过索引定位 ID,再回表查询其他字段,减少回表数据量。
-- 示例:延迟关联优化 SELECT t.* FROM users t JOIN ( SELECT id FROM users WHERE status = 1 LIMIT 100000, 10 ) tmp ON t.id = tmp.id;使用缓存
高频查询结果缓存到 Redis,减少数据库压力。
总结流程图
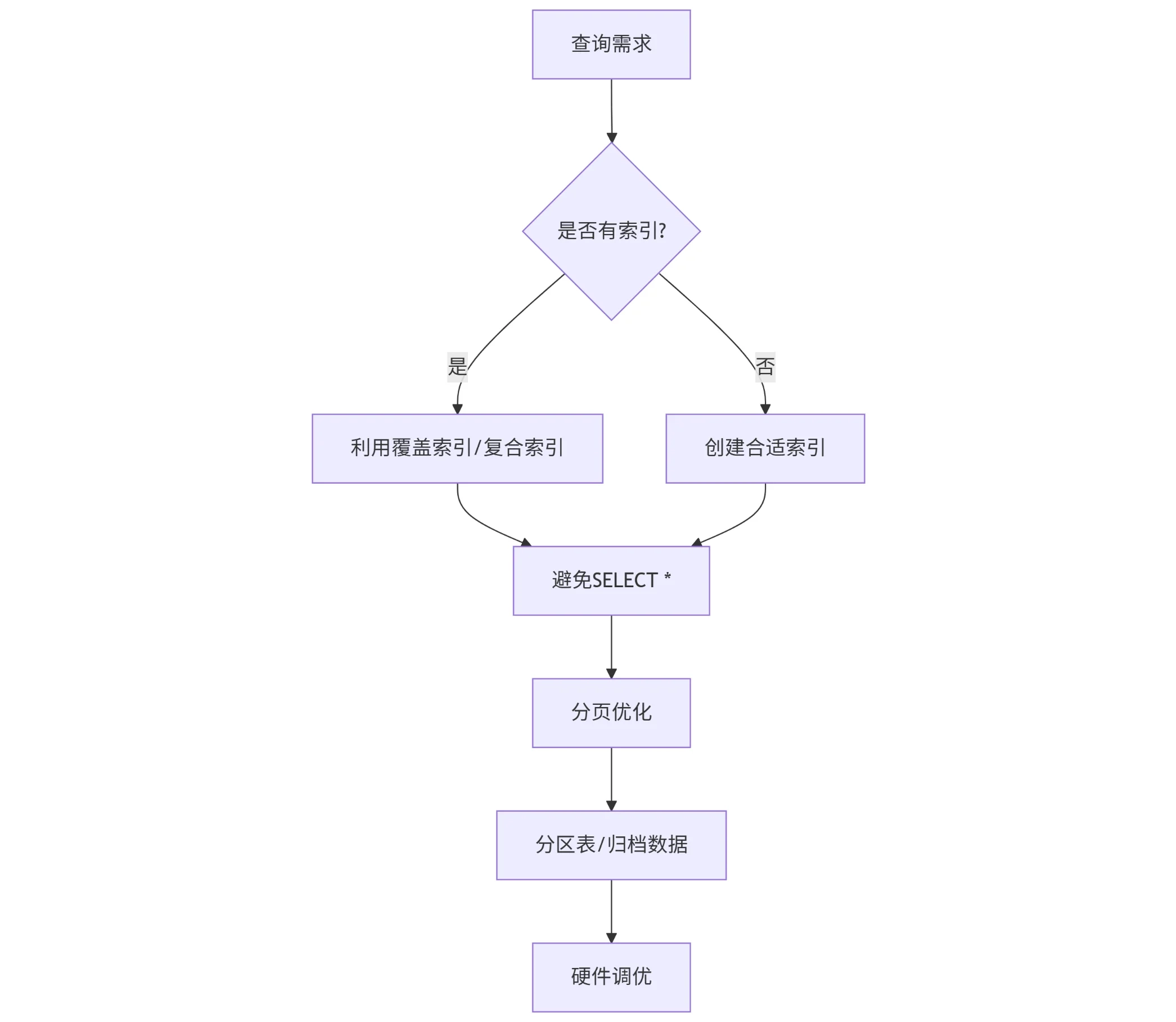
通过以上优化,500 万数据表的单条查询可控制在 毫秒级响应。实际执行前建议用 EXPLAIN 分析执行计划,验证索引是否生效。